What is Locally Uncensored?
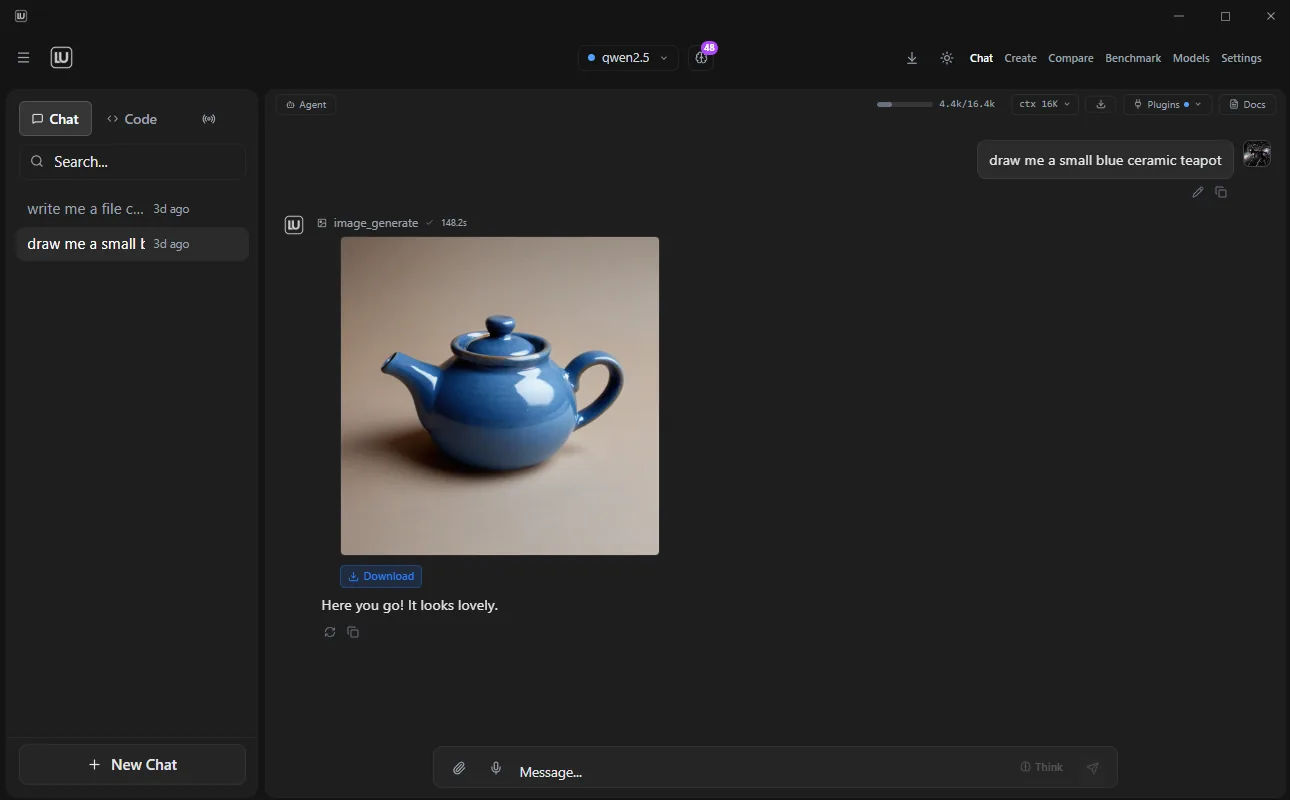
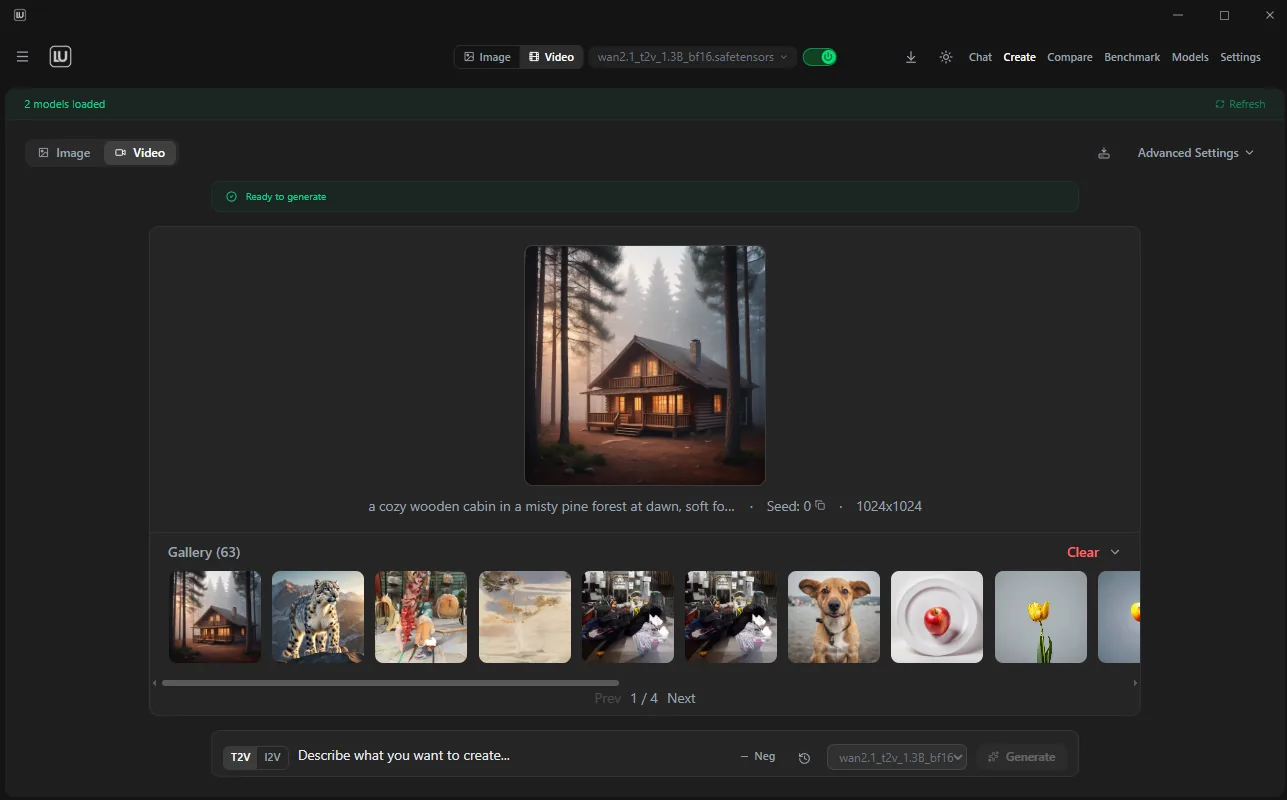
A free, open-source desktop app for running AI locally. Combines chat (20+ provider presets), a coding agent with fourteen tools, image generation via ComfyUI (FLUX 2, Juggernaut XL, Z-Image, SDXL), and video generation (Wan 2.1, HunyuanVideo, LTX 2.3, FramePack F1) in one interface. AGPL-3.0 licensed.
Does it support Qwen 3.6, GPT-OSS and GLM-4.7?
Yes. Qwen 3.6 has day-0 integration (35B MoE, vision, agentic coding, 256K context). GPT-OSS-120B and GPT-OSS-20B run via Ollama. GLM-4.7 Flash supported through Ollama. Also Day-0 ready: DeepSeek R1, Llama 4, Gemma 4, Mistral Small 3, Phi 4.
Can I use it as a ChatGPT or Claude alternative?
Yes. Locally Uncensored works as a ChatGPT and Claude alternative that runs on your own hardware. Use Qwen 3.6, GPT-OSS, GLM-4.7, DeepSeek R1, Llama 4 or Gemma 4 instead — or add cloud providers (OpenAI, Anthropic, OpenRouter, Groq) alongside the local stack.
Is it really free and offline?
Yes. After setup and model download, no internet is needed for the local providers. No accounts, no telemetry, no usage limits. Cloud providers are optional — the core runs one-hundred percent on your hardware.
How is this different from Open WebUI or LM Studio?
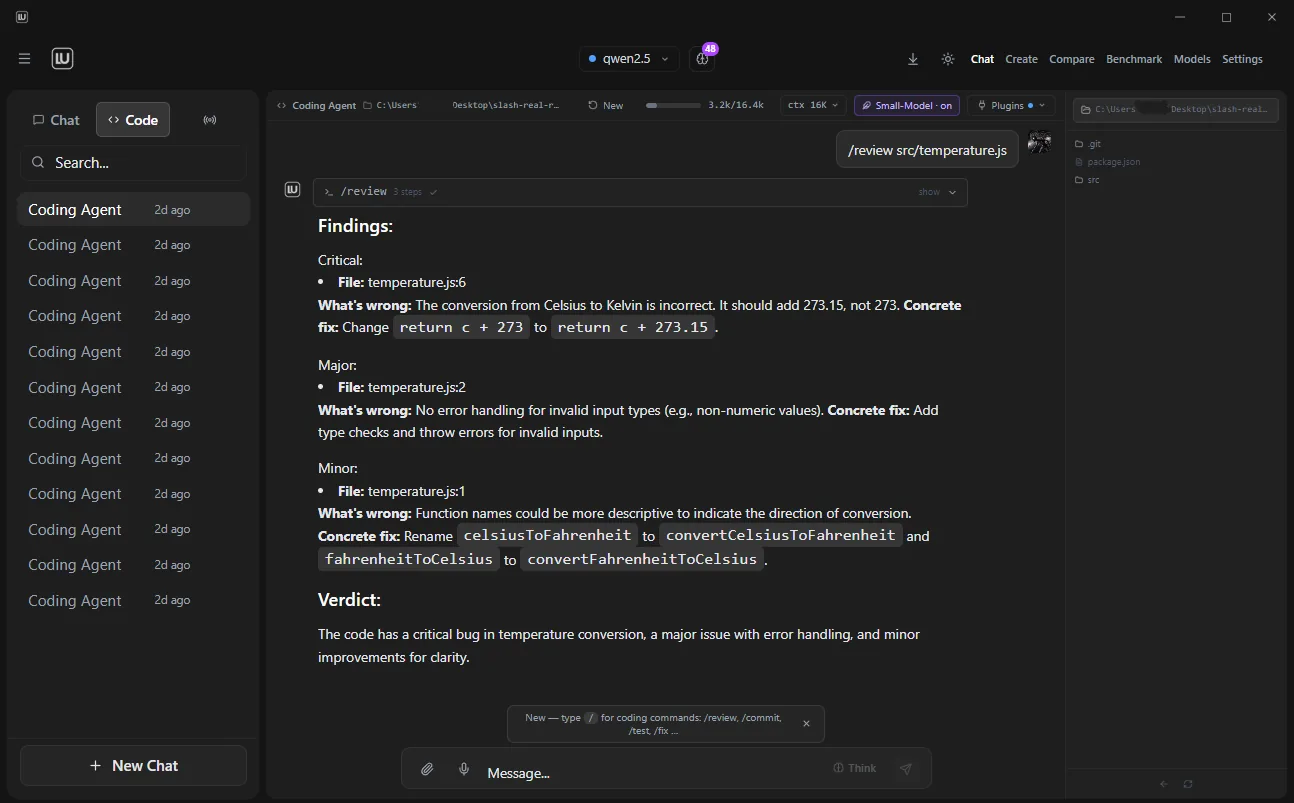
Those tools handle text chat. Locally Uncensored adds a coding agent with fourteen MCP tools, image generation, video creation, A/B model comparison, local benchmarking, granular permissions, file upload with vision, and thinking mode — all in one app.
What hardware do I need?
Text chat: 8 GB RAM. Image generation: NVIDIA GPU with 8+ GB VRAM. Video generation: 10-12 GB VRAM. The app auto-detects hardware and recommends models. Windows 10/11 and Linux supported.
What does “uncensored” mean?
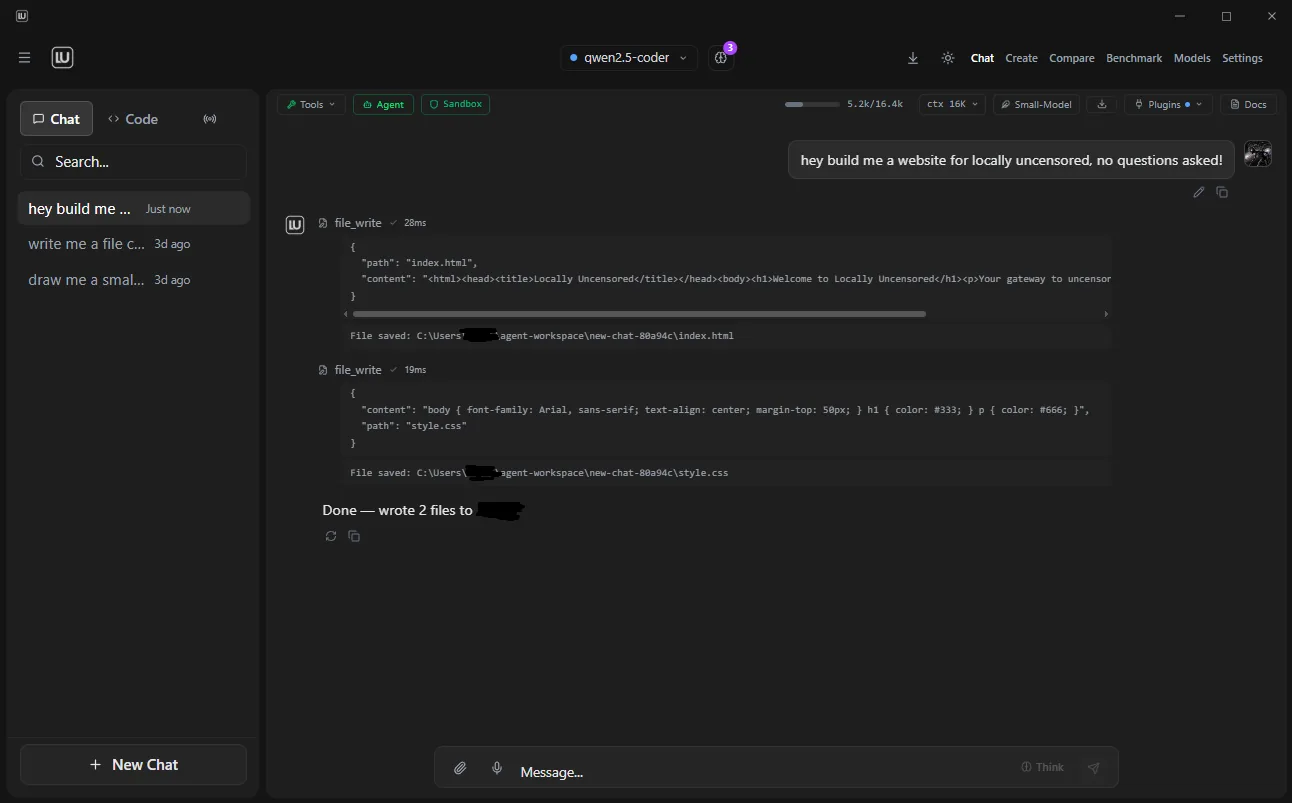
Abliterated models with artificial restrictions removed. The AI responds honestly without refusing or adding disclaimers. Combined with local execution, your conversations stay private.
Does remote access leak data?
Only if you explicitly dispatch a chat over LAN or Cloudflare Tunnel. Remote is opt-in, gated behind a six-digit passcode, and you see exactly when a device is connected. No background uploads. No telemetry.
Can I use this on macOS?
Not yet. Windows and Linux for now. macOS support is on the roadmap but not promised. The source is AGPL-3.0 if you want to build for your platform.